library(ISLR)
library(dplyr)
MyCarseats <- Carseats %>% mutate(SaleHigh=ifelse(Sales > 7.5, "Yes", "No"))
MyCarseats <- MyCarseats %>% select(-Sales)
MyCarseats$SaleHigh <- as.factor(MyCarseats$SaleHigh)
set.seed(123) # for reproducibility
index_tr <- sample(x=1:nrow(MyCarseats), size=0.8*nrow(MyCarseats), replace=FALSE)
df_tr <- MyCarseats[index_tr,]
df_te <- MyCarseats[-index_tr,]Models: Support Vector Machine
Support Vector Machine (SVM)
In this exercise, we apply the Support Vector Machines (SVM) to the classification problem of the data set Carseats from the package ISLR (already used with CART).
SVM are often difficult to interpret. They are typically what we call “a black box” model, that is, a model which provides predictions without understanding what is behind (except if you have followed the course…) and how the features influences these predictions. Therefore, and because we do not want to get bored, we will also use the caret::train() function to make our first real machine learning application. Note that this application can be done also with the models that have been seen previously.
Prepare the data
The lines below are just a repetition/reminder of the CART series to have the data ready. The only difference is the cast of SalesHigh into factors rather than characters because the SVM functions require it.
To proceed we first have to build the data (below is the) Install the package ISLR in order to access the data set Carseats. Use ?Carseats to read its description.
To apply a classification of the sales, we first create a categorical outcome SaleHigh which equals “Yes” if Sales > 7.5 and “No” otherwise. Then we create a data frame MyCarseats containing SaleHigh and all the features of Carseats except Sales. Finally, split MyCarseats into a training and a test set (2/3 vs 1/3). Below we call them df_tr and df_te.
Linear SVM
The e1071::svm() function of the e1071 package allows to fit SVM to the data with several possible kernels. Below, it is the linear kernel. We fit a linear kernel and check the predictions on the test set.
Call:
svm(formula = SaleHigh ~ ., data = df_tr, kernel = "linear")
Parameters:
SVM-Type: C-classification
SVM-Kernel: linear
cost: 1
Number of Support Vectors: 101
obs
Pred No Yes
No 38 8
Yes 3 31To obtain a better insight about the prediction quality, we will use the accuracy measure. It is simply the proportion of correct predictions. This can be conveniently obtained (and much more) from the function caret::confusionMatrix() of the library caret. In the parameters, data are the predictions, and reference are the observations.
Confusion Matrix and Statistics
Reference
Prediction No Yes
No 38 8
Yes 3 31
Accuracy : 0.8625
95% CI : (0.7673, 0.9293)
No Information Rate : 0.5125
P-Value [Acc > NIR] : 4.301e-11
Kappa : 0.724
Mcnemar's Test P-Value : 0.2278
Sensitivity : 0.9268
Specificity : 0.7949
Pos Pred Value : 0.8261
Neg Pred Value : 0.9118
Prevalence : 0.5125
Detection Rate : 0.4750
Detection Prevalence : 0.5750
Balanced Accuracy : 0.8609
'Positive' Class : No
We should only focus on the accuracy for now (the other measures will be studied later). In our run, it was ≈\(86\%\). That number is obtained using the default parameter, cost \(C=1\).
# The usual loading of our environment
library(reticulate)
use_condaenv("MLBA", required = TRUE)Similar to the CART exercises, we use the df_train and df_te created in R to carry out our SVM training. Once again, we continue using the sklearn library. First, we copy our dataset from the R variable to a python variable. Then we use LabelEncoder() from sklearn.preprocessing to convert categorical data into a numeric form, which many sklearn machine learning algorithms require. The encoding assigns a unique numerical value to each categorical value, which can sometimes help the performance. In the case of caret::train(), the function handles this transformation automatically. Also, we standardize the data in the case of python for faster computations using StandardScaler, because of the same numerical stability mentioned for CART. After this, we divide the training and test sets into predictors (e.g., X_train) and the outcome (e.g., y_train) and initialize our linear kernel SVM to fit the model to the data.
We will use classification_report and accuracy_score from sklearn.metrics to get more information on the performance. (you could also use confusion_matrix from the same module.)
import pandas as pd
import numpy as np
from sklearn import svm
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.metrics import classification_report, accuracy_score, confusion_matrix
# We copy the training and testing datasets from R to Python.
# Use r.df_tr to access R objects from Python
carset_tr_py = r.df_tr.copy()
carset_te_py = r.df_te.copy()
# We encode categorical variables as numeric, which is necessary for SVM.
le = LabelEncoder()
cat_vars = ["ShelveLoc", "Urban", "US", "SaleHigh"]
for var in cat_vars:
# Fit the LabelEncoder to the training set and transform the training and testing sets
# We need to use the same encoder for both sets to ensure consistency
carset_tr_py[var] = le.fit_transform(carset_tr_py[var])
carset_te_py[var] = le.transform(carset_te_py[var])
# Split the data into training and testing sets
X_train, y_train = carset_tr_py.drop(columns=["SaleHigh"]), carset_tr_py["SaleHigh"]
X_test, y_test = carset_te_py.drop(columns=["SaleHigh"]), carset_te_py["SaleHigh"]
# Standardize only the continuous variables
cont_vars = ["CompPrice", "Income", "Advertising", "Population", "Price", "Age", "Education"]
scaler = StandardScaler()
X_train[cont_vars] = scaler.fit_transform(X_train[cont_vars])
X_test[cont_vars] = scaler.transform(X_test[cont_vars])
# To speed up the operation you can also transform the inputs
# X_train = X_train.to_numpy()
# y_train = y_train.to_numpy()
# Set random seed for reproducibility
np.random.seed(123)
# Initialize a linear SVM model
carseats_svm_py = svm.SVC(kernel="linear")
# Fit the SVM model to the training data
carseats_svm_py.fit(X_train, y_train);
# Print the model parameters
print(carseats_svm_py)
# Make predictions on the test set
carseats_svm_pred_py = carseats_svm_py.predict(X_test)
# Print a confusion matrix
print(pd.crosstab(index=y_test, columns=carseats_svm_pred_py, rownames=['True'], colnames=['Predicted']))
# Alternatively, print a confusion matrix using `sklearn.metrics`
# print(confusion_matrix(y_test, carseats_svm_pred_py))
# Compute metrics
report_linear_py = classification_report(y_test, carseats_svm_pred_py, target_names=['No', 'Yes'])
accuracy_linear_py = accuracy_score(y_test, carseats_svm_pred_py)
print(report_linear_py)
print("Overall accuracy:", accuracy_linear_py)SVC(kernel='linear')
Predicted 0 1
True
0 38 3
1 15 24
precision recall f1-score support
No 0.72 0.93 0.81 41
Yes 0.89 0.62 0.73 39
accuracy 0.78 80
macro avg 0.80 0.77 0.77 80
weighted avg 0.80 0.78 0.77 80
Overall accuracy: 0.775This performance is worse than our model in R and requires more tuning (due to differences in default values and implementations of the functions).
Radial basis SVM
We try now with a radial basis kernel (the default).
Call:
svm(formula = SaleHigh ~ ., data = df_tr, kernel = "radial")
Parameters:
SVM-Type: C-classification
SVM-Kernel: radial
cost: 1
Number of Support Vectors: 195
Confusion Matrix and Statistics
Reference
Prediction No Yes
No 39 13
Yes 2 26
Accuracy : 0.8125
95% CI : (0.7097, 0.8911)
No Information Rate : 0.5125
P-Value [Acc > NIR] : 2.438e-08
Kappa : 0.6222
Mcnemar's Test P-Value : 0.009823
Sensitivity : 0.9512
Specificity : 0.6667
Pos Pred Value : 0.7500
Neg Pred Value : 0.9286
Prevalence : 0.5125
Detection Rate : 0.4875
Detection Prevalence : 0.6500
Balanced Accuracy : 0.8089
'Positive' Class : No
The accuracy is now ≈\(81\%\). This shows how important that choice can be. In the same vein, we are now relying on the default parameters of the function. For the cost \(C\) it is \(1\), for the parameter gamma of the kernel, it is 1/(data dimension) (see ?svm). The train function allows us to make a better selection.
This is same as the linear kernel, and we just need to change the kernel parameter value from linear to rbf. Here’s the radial version:
np.random.seed(123) # once again, for reproducibility
# Use a radial kernel in the SVM classifier
carseats_svm_rb_py = svm.SVC(kernel="rbf")
carseats_svm_rb_py.fit(X_train, y_train);
print(carseats_svm_rb_py)
# Predict the values with the radial approach
carseats_svm_pred_rb_py = carseats_svm_rb_py.predict(X_test)
# Compute metrics
report_radial_py = classification_report(y_test, carseats_svm_pred_rb_py, target_names=['No', 'Yes'])
accuracy_radial_py = accuracy_score(y_test, carseats_svm_pred_rb_py)
# Print metrics
print(pd.crosstab(index=y_test, columns=carseats_svm_pred_rb_py, rownames=['True'], colnames=['Predicted']))
print(report_radial_py)
print("Overall accuracy:", accuracy_radial_py)SVC()
Predicted 0 1
True
0 36 5
1 15 24
precision recall f1-score support
No 0.71 0.88 0.78 41
Yes 0.83 0.62 0.71 39
accuracy 0.75 80
macro avg 0.77 0.75 0.74 80
weighted avg 0.77 0.75 0.75 80
Overall accuracy: 0.75In both cases (R & python), with the default parameters, the linear kernel seems to do better than the radial one.
Tuning the hyperparameter
In R, caret uses various libraries to run the svm models (check for yourself by searching for support vector machine here). For instance, calling svmLinear or svmRadial uses the library kernlab, and the kernlab::ksvm() function.
The C hyperparameter (from kernlab::ksvm()) accounts for the cost argument and controls the trade-off between allowing misclassifications in the training set and finding a decision boundary that generalizes well to new data. A larger cost value leads to a smaller margin and a more complex model that may overfit the data. On the other hand, a smaller cost value leads to a larger margin and a simpler model that may underfit the data.
Similarly to EX_ML_NN, to select the good hyperparameters, we build a search grid and fit the model with each possible value in the grid. Then, the best model is chosen among all the combinations of the hyperparameters.
As a reminder, the train function from caret. Has:
- a formula.
- a dataset.
- a method (i.e. the model which in this case is SVM with linear kernel).
- a training control procedure.
Linear SVM
trctrl <- trainControl(method = "cv", number=10)
set.seed(143)
svm_Linear <- train(SaleHigh ~., data = df_tr, method = "svmLinear",
trControl=trctrl)
svm_LinearSupport Vector Machines with Linear Kernel
320 samples
10 predictor
2 classes: 'No', 'Yes'
No pre-processing
Resampling: Cross-Validated (10 fold)
Summary of sample sizes: 288, 289, 288, 288, 288, 288, ...
Resampling results:
Accuracy Kappa
0.8814333 0.7627961
Tuning parameter 'C' was held constant at a value of 1For now, the validation accuracy is very high (≈\(89\%\)). This is normal since this accuracy is computed on the training set.
We now supply a grid of values for the cost that we want to try and pass to the argugmenttuneGrid. Be patient, it may take time.
grid <- expand.grid(C = c(0.01, 0.1, 1, 10, 100, 1000))
grid
set.seed(143)
svm_Linear_Grid <- train(SaleHigh ~., data = df_tr, method = "svmLinear",
trControl=trctrl,
tuneGrid = grid)
svm_Linear_Grid
plot(svm_Linear_Grid)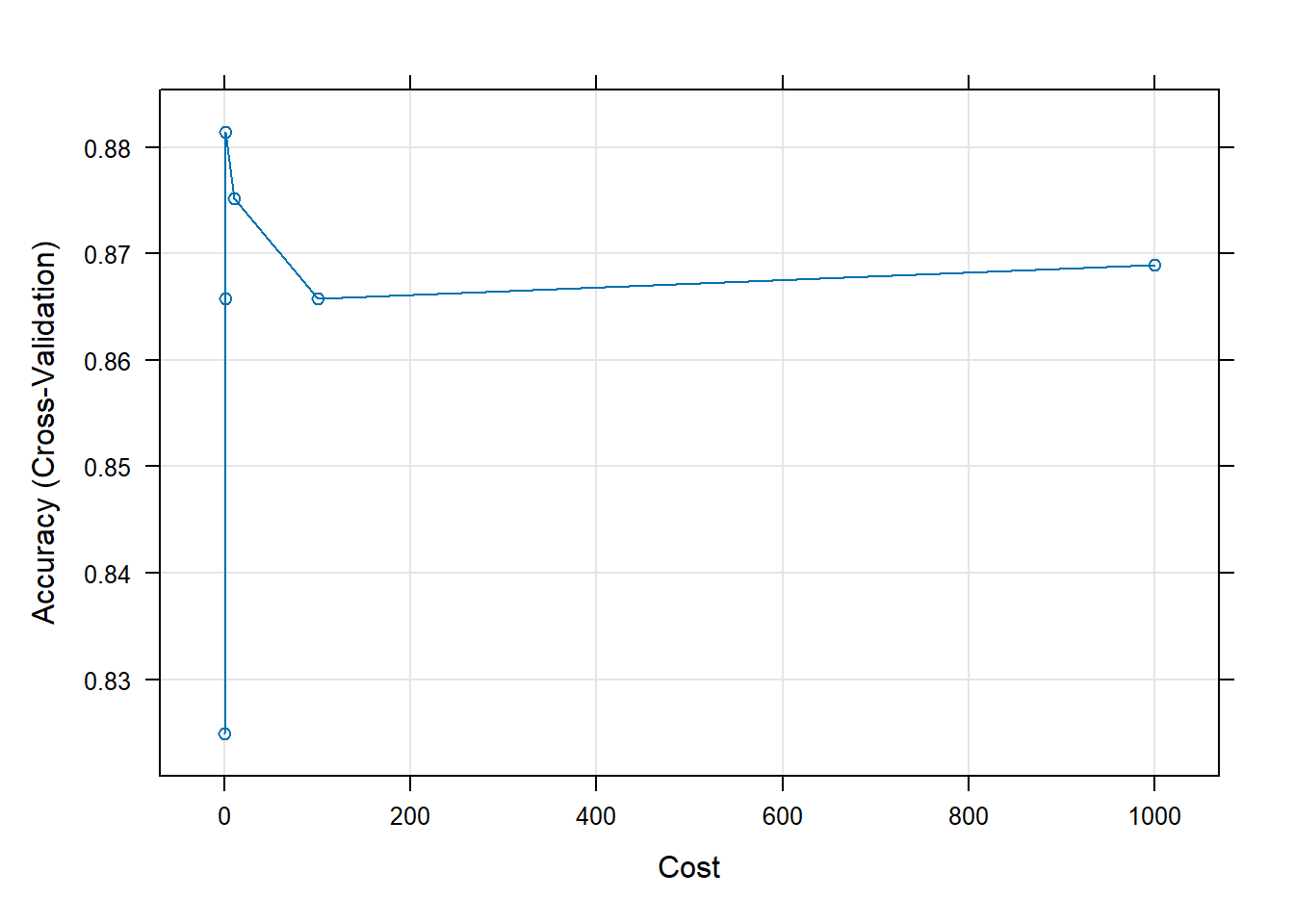
svm_Linear_Grid$bestTune C
1 1e-02
2 1e-01
3 1e+00
4 1e+01
5 1e+02
6 1e+03
Support Vector Machines with Linear Kernel
320 samples
10 predictor
2 classes: 'No', 'Yes'
No pre-processing
Resampling: Cross-Validated (10 fold)
Summary of sample sizes: 288, 289, 288, 288, 288, 288, ...
Resampling results across tuning parameters:
C Accuracy Kappa
1e-02 0.8248809 0.6494001
1e-01 0.8658083 0.7315461
1e+00 0.8814333 0.7627961
1e+01 0.8751833 0.7502961
1e+02 0.8658083 0.7315461
1e+03 0.8689333 0.7377961
Accuracy was used to select the optimal model using the largest value.
The final value used for the model was C = 1.
C
3 1We see that setting the cost to 1 provides the best model. The accuracy apparently reaches a plateau at this value. This is same as our cost parameter in section 1.2.
Radial Basis SVM
The sigma hyperparameter (also from kernlab::ksvm()) controls the width of the radial basis function kernel, which is used to transform the input data into a higher-dimensional feature space. A larger value of sigma corresponds to a narrower kernel and a more complex model, while a smaller value corresponds to a wider kernel and a simpler model.
We repeat the procedure for SVM with a radial basis kernel. Here, there are two parameters ( sigma and C) to tune. The grid choice is rather arbitrary (often the result of trials and errors), and very few general useful guidelines exist. The code below may take a few minutes to run.
grid_radial <- expand.grid(sigma = c(0.01, 0.02, 0.05, 0.1),
C = c(1, 10, 100, 500, 1000))
grid_radial
set.seed(143)
svm_Radial_Grid <- train(SaleHigh ~., data = df_tr, method = "svmRadial",
trControl=trctrl,
tuneGrid = grid_radial)
svm_Radial_Grid
plot(svm_Radial_Grid)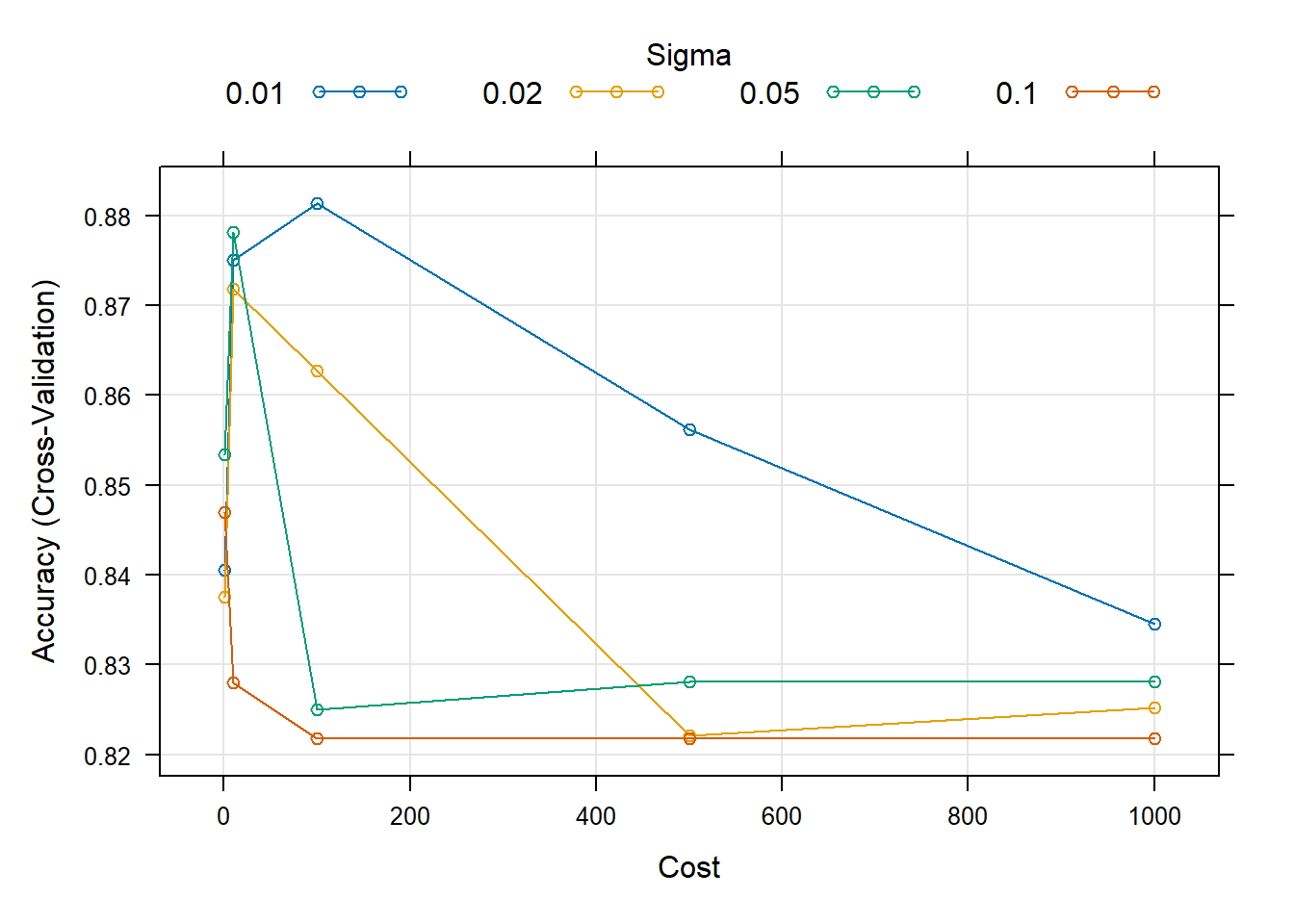
svm_Radial_Grid$bestTune sigma C
1 0.01 1
2 0.02 1
3 0.05 1
4 0.10 1
5 0.01 10
6 0.02 10
7 0.05 10
8 0.10 10
9 0.01 100
10 0.02 100
11 0.05 100
12 0.10 100
13 0.01 500
14 0.02 500
15 0.05 500
16 0.10 500
17 0.01 1000
18 0.02 1000
19 0.05 1000
20 0.10 1000
Support Vector Machines with Radial Basis Function Kernel
320 samples
10 predictor
2 classes: 'No', 'Yes'
No pre-processing
Resampling: Cross-Validated (10 fold)
Summary of sample sizes: 288, 289, 288, 288, 288, 288, ...
Resampling results across tuning parameters:
sigma C Accuracy Kappa
0.01 1 0.8405120 0.6808260
0.01 10 0.8750825 0.7500472
0.01 100 0.8813325 0.7626682
0.01 500 0.8562317 0.7125802
0.01 1000 0.8345461 0.6691401
0.02 1 0.8375825 0.6750472
0.02 10 0.8718567 0.7436694
0.02 100 0.8626833 0.7253900
0.02 500 0.8221408 0.6444015
0.02 1000 0.8251650 0.6504029
0.05 1 0.8534030 0.7067635
0.05 10 0.8782075 0.7564182
0.05 100 0.8249695 0.6501109
0.05 500 0.8280945 0.6563609
0.05 1000 0.8280945 0.6563609
0.10 1 0.8469514 0.6938198
0.10 10 0.8280059 0.6560015
0.10 100 0.8217498 0.6435996
0.10 500 0.8217498 0.6435996
0.10 1000 0.8217498 0.6435996
Accuracy was used to select the optimal model using the largest value.
The final values used for the model were sigma = 0.01 and C = 100.
sigma C
3 0.01 100The optimal model from this search is with sigma = 0.01 and C=100.
We can use GridSearchCV from sklearn.model_selection to achieve the same goal in python and set the argument for cross-validation (cv to achieve the same results) and tune both types of kernels at once. sklearn.svm.SVC() does contain the two arguments for the C and sigma but the relationship is slightly different and we’ll explain below. Also, please note in this approach, the linear kernel by default ignores the sigma values.
As mentioned earlier, in sklearn.svm.SVC(), the equivalent parameter to cost is also C, which is straightforward. Still, the equivalent parameter to sigma is a bit trickier (called gamma in sklearn.svm.SVC()), which also controls the width of the radial basis function kernel. However, the relationship between gamma and sigma differs, and the two parameters cannot be directly compared. In particular, gamma is defined as the inverse of the width of the kernel, i.e., gamma = 1/(2 * sigma**2).
For simplicity’s sake, we’ll directly use the gamma with the same values as sigma; however, you can always run 'gamma': [1/(2*sigma**2) for sigma in [0.01, 0.02, 0.05, 0.1]] to get similar values (although you would want to round as this division results in non-terminating repeating decimal numbers).
The code will take a few minutes to run (longer than the R version).
from sklearn.model_selection import GridSearchCV
np.random.seed(123) # for reproducibility
# Define the grid of hyperparameters to search over
param_grid = {'C': [1, 10, 100, 500, 1000],
'gamma': [0.01, 0.02, 0.05, 0.1],
# 'gamma': [round(1/(2*sigma**2),2) for sigma in [0.01, 0.02, 0.05, 0.1]],
'kernel': ['linear', 'rbf']}
# Perform grid search with cross-validation
grid_search = GridSearchCV(svm.SVC(), param_grid, cv=10, scoring='accuracy', n_jobs=1) # you can also set n_jobs = -1 to use all the cores and obtain the results faster (but unfortunately atm it only works on Mac/Linux and not Windows OS with `reticulate`)
# for more info, please see https://github.com/rstudio/reticulate/issues/1346
grid_search.fit(X_train, y_train);
print("Best hyperparameters:", grid_search.best_params_)
print("Best score:", grid_search.best_score_)Best hyperparameters: {'C': 500, 'gamma': 0.01, 'kernel': 'rbf'}
Best score: 0.853125Note that the accuracy is on the training set. The best parameters are returned bybest_grid_param. We will use a new plotting library for seeing this evolution called seaborn, which offers some great visualization tools.
We use the installed seaborn package from our Setup which allows for grouping our hyperparameters and displaying them with a heatmap.
import seaborn as sns
import matplotlib.pyplot as plt
# Assuming `results` is your DataFrame from `grid_search.cv_results_`
results = pd.DataFrame(grid_search.cv_results_)
# Before performing the pivot or groupby operation, drop the 'params' column (it's a dictionary)
results = results.drop(columns=['params'])
# Now, you can safely group by 'param_C', 'param_gamma', and 'param_kernel' to calculate mean test scores
grouped_results = results.pivot_table(index=['param_C', 'param_gamma'], columns='param_kernel', values='mean_test_score')
plt.clf()
# Create the heatmap
ax = sns.heatmap(grouped_results, annot=True, fmt='.3f', cmap='viridis', cbar=False)
ax.invert_yaxis(); # invert the y-axis to match your preference
plt.xlabel('Kernel');
plt.ylabel('C-Gamma');
plt.show()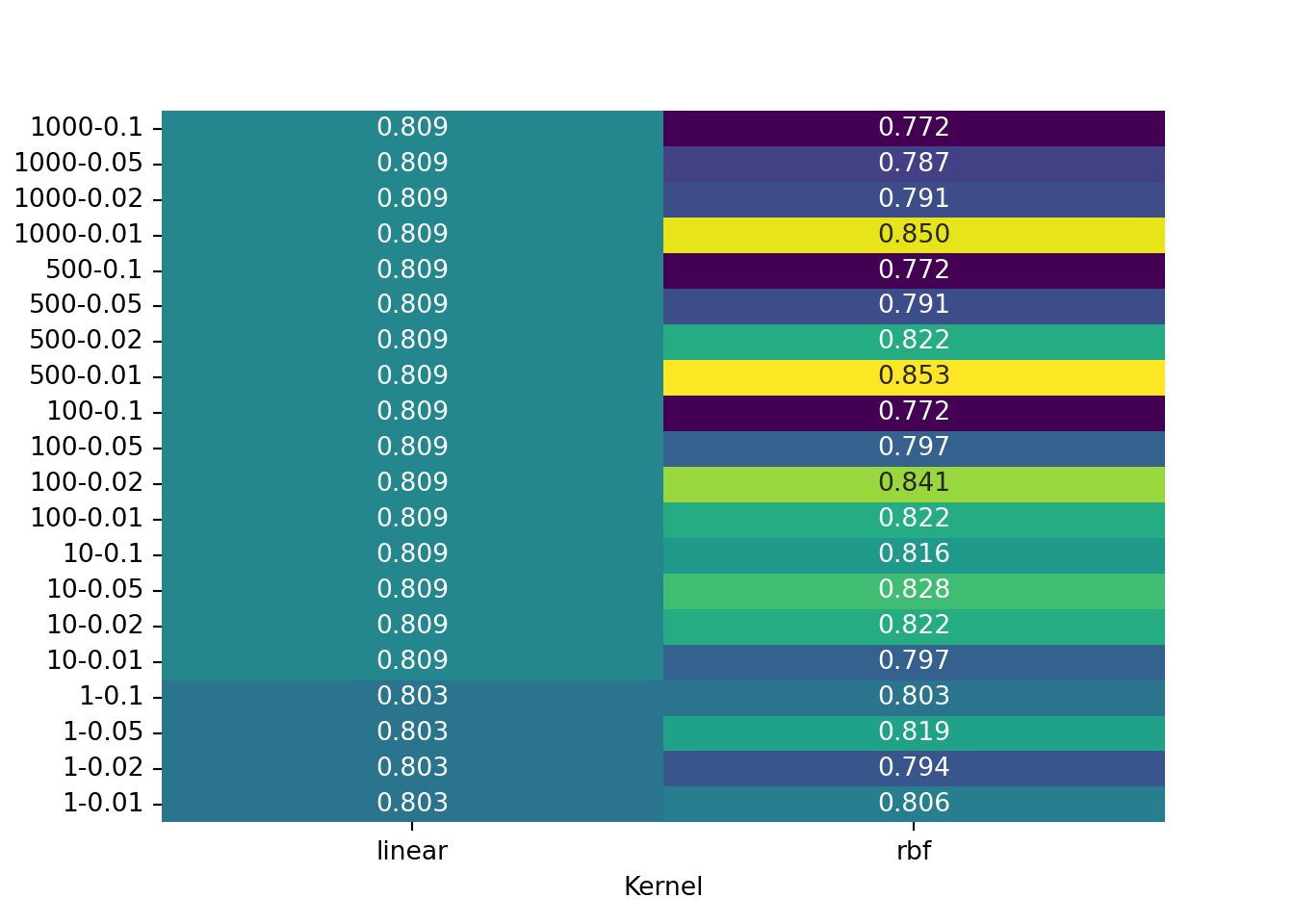
We can see that rbf kernel benefits from changes in C & gamma, however, for the linear, we’re always using the same gamma of 0.01 so for this kernel, the only changes are coming from C parameter.
Best model
After finding the best hyperparameters, it is often good practice to re-train the model with the best hyperparameters on the entire training set before evaluating everything on the test set. We do not need to re-train the model with the entire dataset for the linear SVM, as the best cost matched those used in section 1.2. We re-train the final model with the entire training set using optimal hyperparameters for the radial basis kernel.
carseats_rb_tuned <- svm(SaleHigh ~ .,data = df_tr,
kernel = "radial", gamma = svm_Radial_Grid$bestTune$sigma,
cost = svm_Radial_Grid$bestTune$C)
carseats_rb_tuned_pred <- predict(carseats_rb_tuned, newdata = df_te)
confusionMatrix(data=carseats_rb_tuned_pred, reference = df_te$SaleHigh)Confusion Matrix and Statistics
Reference
Prediction No Yes
No 37 10
Yes 4 29
Accuracy : 0.825
95% CI : (0.7238, 0.9009)
No Information Rate : 0.5125
P-Value [Acc > NIR] : 5.687e-09
Kappa : 0.6485
Mcnemar's Test P-Value : 0.1814
Sensitivity : 0.9024
Specificity : 0.7436
Pos Pred Value : 0.7872
Neg Pred Value : 0.8788
Prevalence : 0.5125
Detection Rate : 0.4625
Detection Prevalence : 0.5875
Balanced Accuracy : 0.8230
'Positive' Class : No
Overall, if we compare all the models, we see that the linear kernel SVM with cost of 1 looks like the best model. We already saw that it provides a \(86\%\) accuracy on the test set. This is what can be expected in the future from that model.
# re-train the model with best hyperparameters
svm_best_py = svm.SVC(**grid_search.best_params_)
svm_best_py.fit(X_train, y_train);
# predict on test dataset
carseats_svm_pred_py = svm_best_py.predict(X_test)
# print confusion matrix and accuracy score
print(pd.crosstab(index=y_test, columns=carseats_svm_pred_py, rownames=['True'], colnames=['Predicted']))
print(classification_report(y_test, carseats_svm_pred_py, target_names=['No', 'Yes']))
print('Accuracy Score:', accuracy_score(y_test, carseats_svm_pred_py))Predicted 0 1
True
0 39 2
1 12 27
precision recall f1-score support
No 0.76 0.95 0.85 41
Yes 0.93 0.69 0.79 39
accuracy 0.82 80
macro avg 0.85 0.82 0.82 80
weighted avg 0.85 0.82 0.82 80
Accuracy Score: 0.825The results are similar to the R outcome for the linear models (except differences in the confusion matrix).
Your turn
Repeat the analysis on the German credit data (german.csv). Since dataset is much larger than MyCarSeats, the tuning procedure may be longer. For this reason, just limit to a linear SVM model for the tuning with limited range for the grid search.